Practical considerations for patenting AI

Artificial intelligence (AI) and machine learning have become increasingly prominent in recent years, providing innovations used across a wide range of technical sectors. AI refers to machines carrying out tasks that would normally be considered to require “human” intelligence. Machine learning refers to a technique in which, by giving a machine training examples, the machine can learn how to do a task without requiring a human to explicitly program the rules for carrying out that task. For example, machine learning algorithms can be used in technical fields as diverse as medical diagnosis, drug discovery, machine vision (such as controlling self-driving cars) and computer virus detection.
Machine learning example
For illustrating use of machine learning, consider the problem of diagnosis of heart arrhythmia based on electrocardiogram (ECG) images. A trained cardiologist may diagnose problems based on the appearance of the ECG trace, but it may be difficult for a computer to perform this task based on rules-based programming.
Instead, a machine learning model is provided which comprises a prediction function defining a mathematical algorithm, configurable based on a set of model parameters, for processing input ECG images to generate a diagnosis.
In a training phase, a training set of ECG images is provided. In a supervised learning approach, each training example is labelled with the “correct” answer (for example, whether the ECG shows a healthy heartbeat or an arrhythmia). A training function is used to adjust the model parameters to minimise error between a predicted diagnosis generated from a training example using the current model parameters and the actual diagnosis represented by the corresponding label.
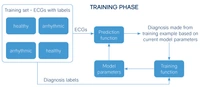
Other model types may use unsupervised training, where training examples are supplied without labels and the training function adapts the model to divide the training examples into clusters with similar properties.
The training phase may continue until the learned model parameters are deemed to give sufficient prediction accuracy (for example, based on testing the model on a further set of test data for which known diagnoses are available). The resulting model parameters can be used by the prediction function in an inference phase to generate diagnoses for new ECGs for which the correct diagnosis is still unknown.
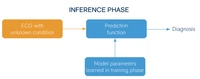
For this reason, rather than operating according to rules prescribed by a human, the machine learning model learns the “rules” from the training data.
What can be protected?
When drafting a patent application, consider including claims for different aspects of the machine learning approach. As different parties may use the model in the training phase and inference phase, it can be useful to provide separate claims directed to the training phase and inference phase respectively.
Machine learning models can be implemented using software executing on a general purpose computer, or using bespoke hardware, such as an application-specific integrated circuit or field programmable gate array. Therefore, for inference phase use of the model, consider claims to both an apparatus and a method or computer program.
For some applications where the generation of the training data set is non-trivial, a claim could also be considered for a method of generating the training data set.
However, as discussed in our previous article, abstract mathematical operations, not tied to a real-world application or technical implementation, are generally considered unpatentable by most patent offices. Therefore, although it is undoubtedly useful for someone to develop a new mathematical algorithm for the prediction and training functions that could be used for a machine learning model applicable to a wide range of fields, unfortunately that innovation would often not be patentable.
In Europe, patentability requires a claimed invention to provide a “technical” contribution. As with other types of mathematical methods, the European Patent Office considers claims to machine-learning-based methods to be excluded from patentability unless either:
- The claim specifies a specific technical purpose for which the method is used; or
- The claim defines a specific technical implementation of the method and the method is particularly adapted for that implementation in that its design is motivated by technical considerations of the internal functioning of the computer.
Other patent offices are less explicit in defining the patentability requirements for machine-learning-based inventions, but similar considerations may apply.
Therefore, unless there is a specific adaptation targeting a given computer platform, machine-learning-based claims may often need to be limited to a specific application in a technical field (e.g. heartbeat monitoring).
Any claimed invention will also need to meet the usual requirements of being new and inventive over what is known in the prior art.
For some machine learning applications, the predicted output generated in the inference phase may itself provide a potentially patentable invention. For example, in drug discovery, a machine learning model could be trained, based on chemical compounds having a known effect for treating a medical condition, to predict which other compounds may also provide that effect. A patent application may claim the predicted compound for use in treatment of the condition. As discussed in our previous article , such AI-derived inventions raise some interesting questions about inventorship and ownership of patent applications.
Considerations for patent drafting
It is important to think carefully about the information included in the specification of a patent for a machine-learning-based invention. There can be a fine line between not disclosing enough information, which risks the patent being refused, and disclosing too much so that competitors gain commercially valuable information when the patent application is published. Deficiencies in the initial disclosure of the patent application are difficult to correct later, as it is not possible to add new information after filing. D Young’s patent attorneys can advise how best to frame the patent specification for a machine-learning-based invention.
For example, patent offices can sometimes be sceptical about patent applications which disclose little more than the bare statement that machine learning could be used for a particular task, without further detail on how to implement the machine learning model. A requirement for grant is that the patent application provides sufficient disclosure of the invention to enable a skilled person in the relevant field could implement the invention. Fortunately, based on current patent office practice, sufficiency does not require disclosure of source code for implementing the machine learning model, the precise set of training data used to train model, or the trained set of model parameters, which may be of considerable value to competitors and so may be considered commercial secrets. This, however, is a fine line to walk since such information could be useful for demonstrating that the invention is not merely a mathematical method.
It can be enough to describe more general features describing how a skilled person could implement the model for carrying out the designated task. Such information should be specific to the implementation of the model for carrying out that task, rather than boilerplate text that describes any machine learning model. For example, consider including information about:
- The type of machine learning model used (for example, neural network, support vector machine). Consider describing any particular algorithmic features or tweaks that may make the model work better for the particular technical application described.
- The format of the input data and the output data for the model.
- How the training set of data was obtained/created (even if the specific training data is not disclosed) and any labels provided for supervised learning. The success of a machine learning model can depend heavily on the nature of the training set (for example, any biases inherent to the training data set may prevent the model working as expected when applied to real-world data), so a description of how to obtain the training set can be important.
- Any criteria for assessing when to end the training phase.
Such information can be useful, to make it plausible to the patent examiner that the applicant has disclosed a practical implementation of the invention, and to provide amendment options that may help distinguish the invention from prior art if necessary to deal with examiner objections.
If available, it can also be useful to include results of analysis of model performance, for example, data showing the accuracy of predictions made by the trained model when applied to a test data set. If different model types or configurations were tested, data showing which options worked better others can also help with establishing inventive step.
Hence, while patents are available for machine-learning-based inventions, care should be taken in drafting the patent application, and so patent attorney advice can be valuable.

